Introduction
Anyone who has used OpenStreetMap (OSM) data in R or python might agree that the tagging system, while it provides great flexibility and extensive classification options, is sometimes a bit challenging to work with. This vignettes will explain the approach to the tagging system that aims to make it easy to interact with features, their associated tags and their geometries. The main ambition being providing an easy access to large OSM data sets.
OSM tags
A tag is a tuple of values, the first element is called a \(key\), while the second is the corresponding \(value\). Together, they form a tag which is written out as a \(key=value\) form. The key corresponds to a broad classification, while the value is specific. For example \(amenity=restaurant\). The \(key\) is \(amenity\), while the \(value\) is \(restaurant\). Generally, there are a few values corresponding to a key. - Every OSM feature consists of a set of nodes and a set of tags. The nodes are geographically referenced, which means they have associated coordinates, allowing to reconstruct the geometry of a feature. A detailed list of possible values and recommendations are available in the following article : OSM map features.
Different data types
To further develop the appropriate tools to work with OSM data, it is important to have a look at what kind of data is actually there and in what format it is most useful. Mainly two types of data can be divided:
Network
First, one main use of OSM data is to obtain connected and routable
road networks, an easy to use function called extrat_graph
will do that. See the corresponding vignette for details. The road
network data is grouped under the \(highway\) key. All categories of roads
(residential,motorway,pedestrian etc…) will be values of this key.
Non network
The rest of the data in OSM is usually represented by either a point or a polygon with its set of associated tags. There can be multiple tags associated to a feature, and one might be interested in the values of a specific one. There is, however, an intrinsic hierarchy in the tags, which can be useful in extracting data in a user friendly and exploitable way.
Tagging hierarchy
This package proposes a 2 level hierarchy of tags, which helps
extract the data into large data.tables or data.frames in which the high
level tags are added as column variables, while secondary tags are
grouped into named lists and added in a separate column called
attrs. The main consideration is that there are tags that
add up information to each other, being complimentary in that sense for
a feature, these are grouped in the 2nd level in this schema. While
there are also tags that are mutually exclusive, for example a tag with
an \(amenity\) key will generally not
have a \(healthcare\) key since these
are different types of features. While both of them can have the same
2nd level keys such as the address, name, phone number or any specific
information.
1st level
The first level corresponds to the main tags. Those are taken from the following list:
main_first_level <- c(
"amenity"
,"craft"
,"healthcare"
,"historic"
,"sport"
,"natural"
,"shop"
,"tourism"
)2nd level
Everything else is left to the second level of tags, for example: \(addr:street\) is a specific key for the address of a feature. It is generally scarce. \(leisure\) is a key that overlaps a lot with the \(sport\) key. It generally contains more specific information on the type of sport.
Explanation
Accounting for the fact that OSM data is crowd sourced and therefore there is somewhere an exception to any kind of rules that can imposed on the data, one can still observe certain patterns that are generally true, this is what this 2 level hierearchy of tags aims to capture. Some observations are:
| 1st level | 2nd level |
|---|---|
|
|
| amenity, shop, tourism etc | addr:name, addr:street, cuisine, takeaway |
Arguably, some tags don’t fall into any of these categories, you can
still export them with the export_data function, such a tag
can be for the \(building\) key. This
qualifies more as a layer of data, much like the road network.
Example
By default, only tags with keys \(amenity,shop,tourism\) will be extracted.
## Linking to GEOS 3.11.0, GDAL 3.5.3, PROJ 9.1.0; sf_use_s2() is TRUE
test_file <- system.file(package = 'cppRosm','extdata','map.osm')
data <- cppRosm::extract_data(test_file)## → Using main keys `amenity`,`shop`,`tourism`.| id | key | value | lon | lat | attrs |
|---|---|---|---|---|---|
| 227734022 | amenity | fuel | 10.513 | 43.850 | Api-Ip , Q646807 , en:Anonima Petroli Italiana , yes , yes , yes , IP , Netti Santo Nicola , 28234 , MISE - Ministero Sviluppo Economico |
| 227808627 | amenity | fuel | 10.495 | 43.841 | Esso , Q867662 , yes , yes , Esso , Ciervo Giovanni, 37277 |
| 227817156 | amenity | fuel | 10.495 | 43.845 | Api-Ip , yes , yes , Cobel - Commercio Benzina Lubrificanti - S.R.L. o Cobel - S.R.L., 31551 , no , yes |
| 227817516 | amenity | fuel | 10.516 | 43.848 | Api-Ip , 2022-09-04 , yes , yes , Giop , Cobel - Commercio Benzina Lubrificanti - S.R.L. o Cobel - S.R.L., yes , yes , yes , 22498 , no , yes |
| 227821623 | amenity | fuel | 10.516 | 43.846 | Agip , Q377915 , en:Agip , yes , yes , Agip , Fratelli Checchi - S.N.C., 39092 |
| 227821625 | amenity | fuel | 10.516 | 43.847 | Api-Ip , yes , yes , Minghi Marco, 8149 , no , yes |
The geometry is simplified to the centroid, for which the coordinates
are provided in the lon,lat columns of the data table.
A function allowing to reconstruct the full geometry is provided, but
since it is not necessarily always usefull to have it, it is ommited in
a first extraction. The nodes that constitute a full geometry, if it is
more complex than a point, are added to the attrs column as a
data.frame. These geometries are always closed, meaning
they are polygons. This is meant to save memory especially for large
data sets.
With this data format, we can now easily manipulate all the POIs, or select specific keys, or specific values, or both.
| id | key | value | lon | lat | attrs |
|---|---|---|---|---|---|
| 227734022 | amenity | fuel | 10.513 | 43.850 | Api-Ip , Q646807 , en:Anonima Petroli Italiana , yes , yes , yes , IP , Netti Santo Nicola , 28234 , MISE - Ministero Sviluppo Economico |
| 227808627 | amenity | fuel | 10.495 | 43.841 | Esso , Q867662 , yes , yes , Esso , Ciervo Giovanni, 37277 |
| 227817156 | amenity | fuel | 10.495 | 43.845 | Api-Ip , yes , yes , Cobel - Commercio Benzina Lubrificanti - S.R.L. o Cobel - S.R.L., 31551 , no , yes |
| 227817516 | amenity | fuel | 10.516 | 43.848 | Api-Ip , 2022-09-04 , yes , yes , Giop , Cobel - Commercio Benzina Lubrificanti - S.R.L. o Cobel - S.R.L., yes , yes , yes , 22498 , no , yes |
| 227821623 | amenity | fuel | 10.516 | 43.846 | Agip , Q377915 , en:Agip , yes , yes , Agip , Fratelli Checchi - S.N.C., 39092 |
| 227821625 | amenity | fuel | 10.516 | 43.847 | Api-Ip , yes , yes , Minghi Marco, 8149 , no , yes |
| id | key | value | lon | lat | attrs |
|---|---|---|---|---|---|
| 1948949391 | amenity | restaurant | 10.506 | 43.846 | Lucca , IT , 9 , 55100 , Via Anfiteatro , regional , info@osteriabaralla.it , wlan , Osteria Baralla , +39 0583 440240 , no , 1860 , https://www.osteriabaralla.it/, limited |
| 1984554026 | amenity | restaurant | 10.502 | 43.843 | Lucca , 3 , 55100 , Via della Cervia , Buca di Sant’Antonio , +39 0583 55881 , http://www.bucadisantantonio.it, limited |
| 1987005332 | amenity | restaurant | 10.506 | 43.845 | Lucca , IT , 38 , 55100 , Piazza Anfiteatro , italian , Osteria del Tortellino |
| 2241788287 | amenity | restaurant | 10.504 | 43.838 | 259 , 55100 , Viale Regina Margherita , Pizzeria La Tana dell’Orco, +39 389 0233234 |
| 2837898251 | amenity | restaurant | 10.507 | 43.849 | 42 , info@trattoriagostoemea.it , Trattoria Gosto e Mea , Tu-Sa 11:30-14:30,19:00-24:00; Su 19:00-24:00; Mo closed, Gosto e Mea s.r.l. , +39 0583 1805200 , trattoria , www.trattoriagostoemea.it , limited |
| 2993594810 | amenity | restaurant | 10.503 | 43.842 | italian , Antica locanda dell’angelo, no |
# both: use or to include specific values of different keys and keys
data[key=="shop" | value=="restaurant",] |> head() |>
knitr::kable(digits = 3)| id | key | value | lon | lat | attrs |
|---|---|---|---|---|---|
| 248908257 | shop | supermarket | 10.499 | 43.849 | Lucca , IT , 565 , 55100 , Viale Carlo Del Prete , Esselunga , Esselunga di viale Del Prete , Mo-Sa 07:30-21:00, Su 09:00-14:00, yes , https://www.esselunga.it/ , yes |
| 645006065 | shop | coffee | 10.505 | 43.845 | NULL |
| 1375297878 | shop | bicycle | 10.507 | 43.847 | Lucca , IT , 42 , 55100 , Piazza Santa Maria , bicycle_rental , Noleggio bicicletta Antonio Poli, +39 0583 493787 , yes , no , yes |
| 1463854336 | shop | optician | 10.504 | 43.844 | Ottico Toni, limited |
| 1463859737 | shop | books | 10.504 | 43.843 | Lucca , 20 , 55100 , Via Roma , Mondadori , Q85355 , en:Arnoldo Mondadori Editore , Mondadori , no , Entrata Via Cenami con campanello assistenza. Entrance Via Cenami with assistance bell. |
| 1531037312 | shop | alcohol | 10.507 | 43.846 | 188 , Via Fillungo, Vinarkía |
Filtering 2nd level tags
A function to efficiently filter the secondary tags returns a data
frame, where the searched for key will be added as a column for all
feature that has a non-NA match. Under the hood, values are
matched using regular expressions, which maximises the chance of finding
the desired values in sometimes complicated OSM values.
data |>
cppRosm::filter_sec(keys=c("cuisine","takeaway")
,cores=1) |>
head() |>
knitr::kable(digits = 3)| id | key | value | lon | lat | attrs | cuisine | takeaway |
|---|---|---|---|---|---|---|---|
| 1463854159 | amenity | fast_food | 10.503 | 43.844 | Lucca , 12 , Via Buia , pizza , Pizza da Felice, no | pizza | NA |
| 1948679522 | amenity | cafe | 10.502 | 43.840 | Lucca , 74 , 55100 , Via Vittorio Veneto , ice_cream , Gelateria Veneta , Gelateria Veneta SRL , +39 0583 467037 , https://www.gelateriaveneta.net/, limited | ice_cream | NA |
| 1948949391 | amenity | restaurant | 10.506 | 43.846 | Lucca , IT , 9 , 55100 , Via Anfiteatro , regional , info@osteriabaralla.it , wlan , Osteria Baralla , +39 0583 440240 , no , 1860 , https://www.osteriabaralla.it/, limited | regional | NA |
| 1987005332 | amenity | restaurant | 10.506 | 43.845 | Lucca , IT , 38 , 55100 , Piazza Anfiteatro , italian , Osteria del Tortellino | italian | NA |
| 1987005335 | amenity | cafe | 10.506 | 43.845 | ice_cream | ice_cream | NA |
| 2969988634 | amenity | bar | 10.503 | 43.839 | 18 , Via Francesco Carrara , japanese;sushi;coffee_shop;italian, Lelemento , Origami , Origami , Origami | japanese;sushi;coffee_shop;italian | NA |
data |>
cppRosm::filter_sec(keys=list("cuisine"=c("japanese","pizza")
,"takeaway"=c("yes"))
,cores = 1) |>
head() |>
knitr::kable(digits = 3)## ℹ Searching for exact key~value matches.| id | key | value | lon | lat | attrs | cuisine | takeaway |
|---|---|---|---|---|---|---|---|
| 1463854159 | amenity | fast_food | 10.503 | 43.844 | Lucca , 12 , Via Buia , pizza , Pizza da Felice, no | pizza | NA |
| 2969988634 | amenity | bar | 10.503 | 43.839 | 18 , Via Francesco Carrara , japanese;sushi;coffee_shop;italian, Lelemento , Origami , Origami , Origami | japanese;sushi;coffee_shop;italian | NA |
| 2993594823 | amenity | restaurant | 10.506 | 43.845 | Lucca , IT , 51 , 55100 , Piazza Anfiteatro, pizza , L’angolo tondo | pizza | NA |
| 2993594832 | amenity | restaurant | 10.503 | 43.843 | pizza , Pellegrini | pizza | NA |
| 2993598933 | amenity | restaurant | 10.502 | 43.843 | italian;pizza, yes , Piccolo Mondo, yes | italian;pizza | NA |
| 2993609216 | amenity | restaurant | 10.503 | 43.842 | Lucca , 16 , 55100 , Piazza Napoleone, pizza , Fuori di piazza , Mo-Sa , yes , limited | pizza | NA |
Geometries
In a lot of cases, knowing the centroids of POIs is more than enough:
data |>
sf::st_as_sf(coords=c("lon","lat"),crs=4326) |>
sf::st_geometry() |>
plot(pch=19)
# or same result, keeping the original data a `data.table`
# data |>
# cppRosm::construct_geom() |>
# sf::st_as_sf() |>
# sf::st_geometry() |>
# plot()But there will be times when the original geometry might be of
interest, in this case use the construct_geom function:
data_geom <- data |>
cppRosm::construct_geom(complete = TRUE,cores = 1) |>
sf::st_as_sf()
data_geom |>
sf::st_geometry() |>
plot(pch=19)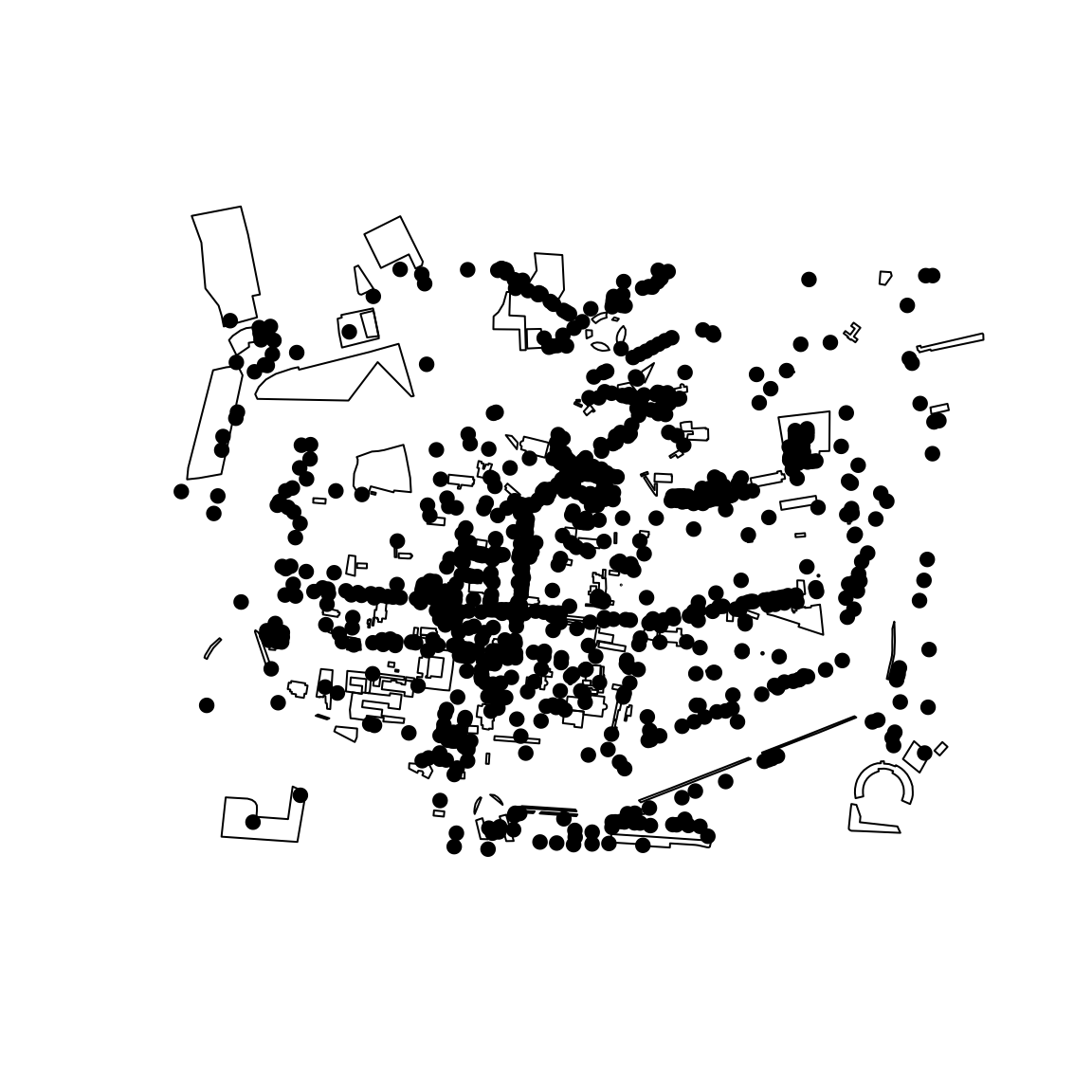
Buildings
As discussed earlier, the tags withe the \(building\) key arguably fall into neither
categories, and in that sense they constitute a data layer, just like
the road network. They can still be queried and extracted with the
extract_data function.
buildings <- cppRosm::extract_data(test_file,main_keys = "building")This function will run in a fraction of seconds and extract all the buildings from the file. It will again only provide the centroid in direct access:
buildings |>
cppRosm::construct_geom() |>
sf::st_set_geometry("geometry") |>
sf::st_geometry() |>
plot(pch=19)
And we can reconstruct the geometries from the data hidden in
attrs as follows:
buildings |>
cppRosm::construct_geom(complete = TRUE,cores=1) |>
sf::st_as_sf() |>
sf::st_geometry() |>
plot(pch=19)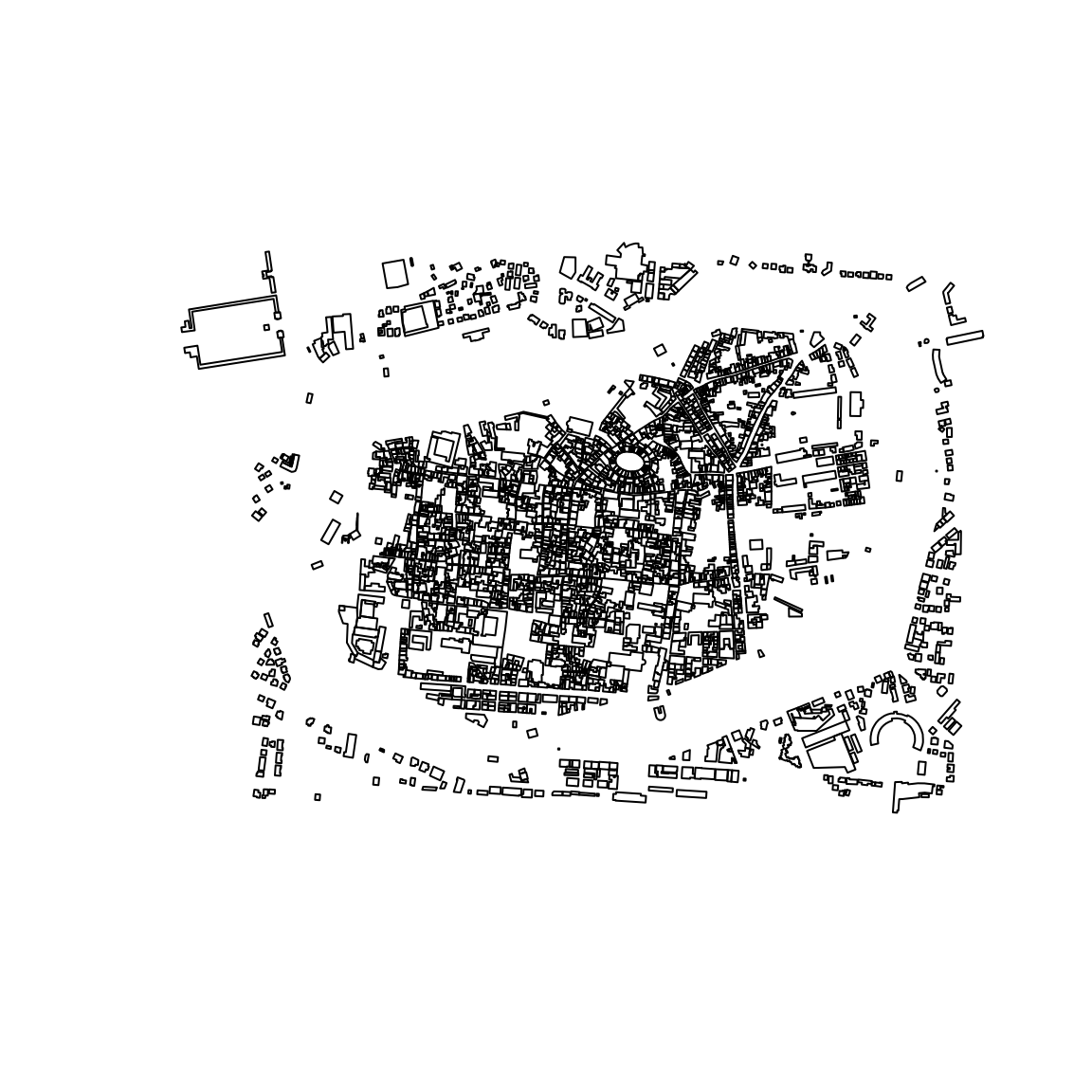
We can filter for specific tags:
buildings |>
cppRosm::filter_sec(keys=c("shop","amenity")) |>
dplyr::select(!attrs) |>
head() |>
knitr::kable(digits = 3)| id | key | value | lon | lat | amenity | shop |
|---|---|---|---|---|---|---|
| 35164444 | building | church | 10.503 | 43.843 | place_of_worship | NA |
| 48981467 | building | church | 10.502 | 43.842 | place_of_worship | NA |
| 48981475 | building | church | 10.500 | 43.843 | place_of_worship | NA |
| 48981487 | building | church | 10.502 | 43.845 | place_of_worship | NA |
| 48981495 | building | church | 10.509 | 43.842 | place_of_worship | NA |
| 48981496 | building | church | 10.508 | 43.846 | place_of_worship | NA |
We observe the mutually exclusive nature of \(amenity\) and \(shop\) keys, justifying the earlier discussion and the differentiation of the \(building\) key. The only intersection of the two keys is the famous in french bar-tabac, which is both a bar and a place to buy tobacco/cigarettes.
More specific filtering:
buildings |>
cppRosm::filter_sec(keys = list("tourism" = c("")
,"abandoned" = c("yes"))) |>
dplyr::select(!attrs) |>
head() |>
knitr::kable(digits = 3)## ℹ Searching for exact key~value matches.| id | key | value | lon | lat | tourism | abandoned |
|---|---|---|---|---|---|---|
| 120076875 | building | tower | 10.507 | 43.844 | viewpoint | NA |
| 141364087 | building | yes | 10.512 | 43.845 | museum | NA |
| 180148954 | building | yes | 10.503 | 43.846 | attraction | NA |
| 180148963 | building | yes | 10.501 | 43.841 | attraction | NA |
| 180148964 | building | public | 10.503 | 43.840 | attraction | NA |
| 180148975 | building | church | 10.504 | 43.843 | attraction | NA |
If searching for a specific \(key=value\) in one tag and all values for another tag, consider the trick above.
- It’s generally not recommended to extract the building layer together with other main keys.
Alternatives
-
osmdata: while this is a great package that I have used a lot, I found it frustrating to have all the different geometries gathered into separate tables, and each table containing huge numbers ofNAcolumns. Theattrscolumn in a cppRosm table provides an alternative way to store all the secondary tags. Additionally, all the geometries are simplified to their centroid, but the possibility to reconstruct the original ones are provided with theconstruct_geomfunction. -
osmextract: great for working with large OSM files. But the filtering of features remains a bit obscure in my opinion, although it seems to provide great flexibility, but requires a good knowledge of OSM internals.
Conclusion
This vignette aimed to explain the approach taken for manipulating OSM data at scale and with flexibility through a specific data table format and supporting functions. Please reach out for recommendations, feature additions etc…
In another vignette, a recommended workflow will be covered, as this
package was developed with a few others in mind
(rosmium,cppRouting mainly) , so that network
and POI analysis could be done at scale in a local setup.